Spending Data Handbook
The data processing pipeline
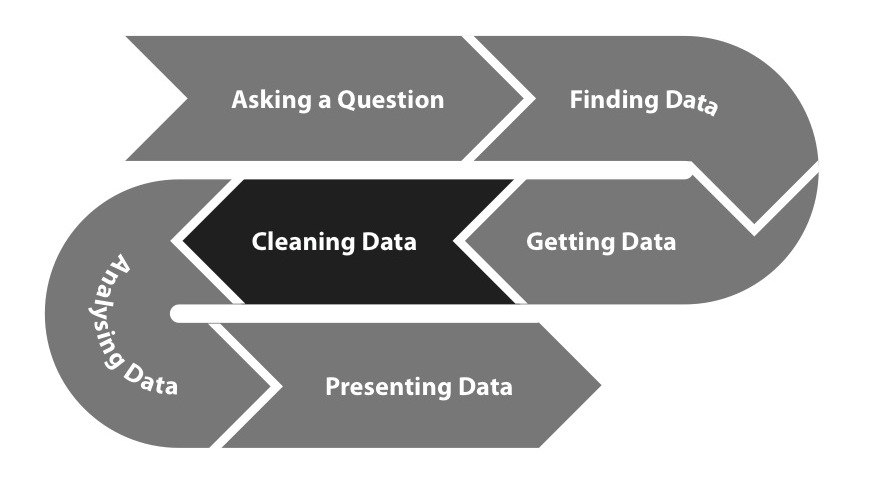
The data processing pipeline
While there are many different types of data, almost all data processing involves the same set of incremental stages.
- Acquisition. Data is gathered or new data is generated (e.g through a survey, observations, or experiments).
- Extraction. Data is converted from whatever input format has been acquired (e.g. XLS files, PDFs, or even plain text documents) into a form that can be used for further processing and analysis. This often involves loading data into a database system like MySQL or PostgreSQL.
- Cleaning and transformation. Errors, inconsistencies, and duplicates are removed from the data. You may also combine two different datasets into a single table at this stage.
- Analysis. Data is analyzed to address the research question. We will not cover analysis in great detail in the Handbook—we assume that you are already the experts in working with your data and using e.g. economic models to answer your questions.
- Presentation. The analysis of the data is presented in a form which is understandable to a particular audience and designed to achieve a particular outcome.
In this section of the Handbook, we will cover stages 1 through 4. The next section, "Presentation and Engagement", will cover stage 5.